
이 글은 문자를 인코딩 및 디코딩 하는 방식에 대해 정리한 글이다.
문자 집합과 인코딩
컴퓨터가 문자를 이해하기 위해서는 문자가 0과 1로 표현되어야 한다. 문자 집합(Character Set)은 컴퓨터가 인식하고 표현할 수 있는 문자의 모음을 의미한다. 문자 집합에 포함되어 있는 문자는 컴퓨터가 이해할 수 있는 문자이고, 만약 문자 집합에 포함되어 있지 않다면 이해할 수 없는 문자가 된다.
컴퓨터가 이해하기 위해서는 문자를 0과 1로 표현해야 하는데, 우리가 일반적으로 사용하는 알파벳이나 한글과 같은 문자가 0과 1로 변환되는 과정을 문자 인코딩(Character Encoding)이라고 한다. 이렇게 문자 인코딩 과정을 거치면 0과 1로 문자가 변환되어 컴퓨터가 비로소 이해하게 된다. 문자 인코딩의 반대 과정을 문자 디코딩(Character Decoding)이라고 한다. 즉, 문자 디코딩은 0과 1로 이루어진 문자 코드를 사람이 이해할 수 있는 알파벳이나 한글과 같은 문자로 변환하는 과정을 의미한다.
아스키(ASCII) 코드
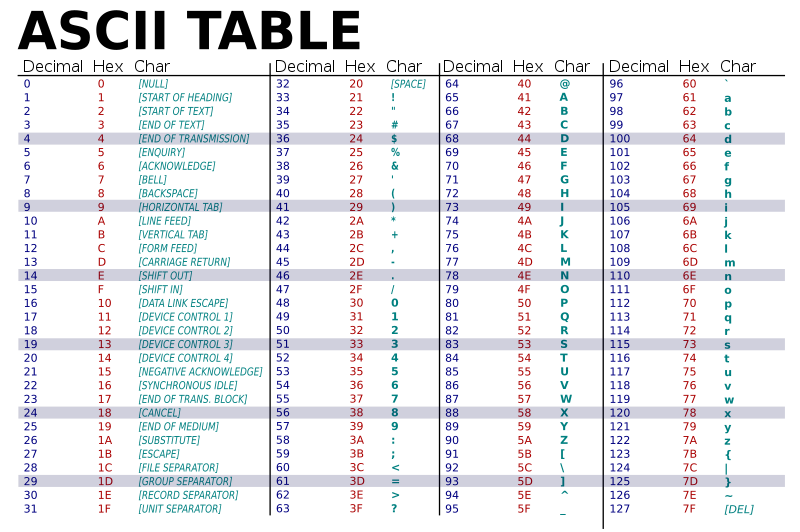
아스키(ASCII)는 American Standard Code for Information Interchange(미국정보교환표준코드)의 약자로, 초창기에 사용되었던 문자 집합 중 하나이다. 아스키에는 영어 알파벳(대소문자)과 아라비아 숫자(0 ~ 9), 일부 특수 문자가 포함되어 있으며, 각 문자는 7비트로 표현되어 총 128개의 문자를 표현할 수 있다.
✔️ 패리티 비트(perity bit)
실제로 아스키 문자 하나를 나타낼 때 8비트(1바이트)를 사용하지만, 8비트 중 1비트는 오류 검출을 위해 사용된다. 이렇게 오류 검출에 사용되는 비트를 패리티 비트(perity bit)라고 하며, 오류 검출 1비트와 문자 표현 7비트가 합쳐 총 8비트로 하나의 아스키 문자를 표현하게 된다. 오류 검출용인 패리티 비트를 제외하면 7비트만을 사용하여 문자를 표현하기 때문에 128개의 문자를 표현할 수 있는 것이다.
위에서 볼 수 있는 이미지가 바로 각 문자에 대응되는 아스키 코드이다. 아스키 문자에 대응되는 숫자를 아스키 코드라고 하며, 이 아스키 코드를 이진수로 표현함으로서 아스키 문자를 0과 1로 표현할 수 있게 된다. 위 아스키 코드표를 참고하여 보면, A는 십진수 65에 대응되어 있으며, 이는 십육진수로는 \( 41_{(16)} \)로 표현하며 이진수로 바꾸면 \( 1000001_{(2)} \)가 된다. 아스키 코드에는 문자 및 특수 문자 이외에도 제어 문자라고 하는 BACKSPACE나 SPACE와 같은 것도 포함되어 있다.
아스키 코드는 간단하게 인코딩된다는 장점이 있지만, 7비트로 문자를 표현하여 128개라는 적은 개수의 문자만을 표현할 수 있다는 단점이 있다. 쉽게 생각하면 아스키 코드로는 한글을 표현할 수 없으며, 표에 제시된 특수 문자 이외에 ★과 같은 특수 문자는 사용할 수 없는 것이다. 그래서 조금 더 다양한 문자를 표현하기 위해 확장 아스키(Extened ASCII)*가 등장하기도 하였지만, 영어권 이외의 국가들에서는 고유 문자를 표현할 수 있는 방법이 없었기 때문에 영어 알파벳 이외의 고유 문자를 표현하기 위해 새로운 문자 집합에 대한 인코딩 방식이 등장하게 되었다.
* 확장 아스키(Extended ASCII) : 기존 아스키에서 더 다양한 문자를 표현하기 위해 1비트를 추가한 8비트로 문자를 표현하는 방식. 128개에서 256개로 표현할 수 있는 문자의 개수가 증가함.
EUC-KR
한글은 알파벳과 달리 표현할 수 있는 방식이 두 가지가 있다. 영어는 알파벳을 쭉 이어 쓰면 단어가 만들어지지만, 한글은 하나의 음절을 만들어내기 위해 자음과 모음이 초성, 중성, 종성에 각각 조합되어야 한다. 그래서 한글 인코딩 방식은 크게 완성형(한글 완성형 인코딩)*과 조합형(한글 조합형 인코딩)** 방식이 존재한다.
* 완성형 인코딩 : 초성, 중성, 종성의 조합으로 이루어진 하나의 글자에 고유한 코드를 부여하여 인코딩하는 방식
** 조합형 인코딩 : 초성의 비트열, 중성의 비트열, 종성의 비트열을 각각 할당하여 이들의 조합으로 하나의 글자 코드를 완성하는 인코딩 방식
EUC-KR은 대표적인 완성형 인코딩 방식 중 하나이다. 문자 집합으로는 KS X 1001와 KS X 1003을 사용하며, 글자 하나에 2바이트(16비트) 크기의 코드를 부여한다.
✔️ 확장 유닉스 코드(EUC)
EUC는 Extended Unix Code의 약자로, 한국어, 중국어, 일본어의 문자 전산화에서 사용되는 8비트 문자 인코딩 방식이다. EUC의 구조는 ISO-2022 표준을 기반으로 하고 있으며, 한국은 EUC-KR, 중국은 EUC-CN, 대만에서는 EUC-TW, 일본은 EUC-JP를 사용한다. (다른 인코딩 방식들도 존재하기 때문에 EUC 방식을 사용하는 빈도는 국가마다 차이가 있다. 한국에서는 EUC-KR을 많이 사용하고 있다.)
EUC-KR 방식을 사용하면 총 2350개 정도의 한글 글자를 표현할 수 있다. 아스키 코드에 비하면 20배에 가까운 글자를 표현할 수 있지만, 한글의 조합으로 나타낼 수 있는 모든 글자 조합을 표현할 수 있는 것은 아니라는 단점도 존재한다. (대표적으로 "뷁"과 같은 글자는 EUC-KR로 표현할 수 없다.) 더 많은 문자를 표현하기 위해 EUC-KR의 확장된 버전으로 마이크로소프트의 CP949(Code Page 949)라는 인코딩 방식도 존재한다. (파이썬의 pandas를 사용하는 분들은 한글이 포함된 파일을 불러올 때 많이 봤을 것이다.)
유니코드와 UTF-8
아스키 코드는 영어 알파벳만 표현할 수 있다는 단점이 있고, EUC 인코딩 방식은 국가마다 서로 다른 인코딩 방식을 사용한다는 단점이 존재한다. 이는 여러 언어를 사용하는 프로그램을 개발할 때, 각 국가에 맞는 인코딩 방식을 모두 사용해야한다는 의미가 된다.
이러한 문제(단점)를 해결하기 위해, 모든 언어를 포함하고 있는 문자 집합과 통일된 표준 인코딩 방식이 존재하는데, 이러한 방식이 바로 유니코드(Unicode)이다. 유니코드는 한글만을 놓고 봐도 EUC-KR보다 많은 양의 한글을 표현할 수 있으며, 대부분 국가의 문자, 특수 문자, 화살표, 이모티콘 등 다양한 것을 코드로 표현할 수 있다. 그래서 현재는 유니코드가 가장 많이 사용되는 표준 문자 집합이다. 아래 링크에서는 유니코드를 직접 확인해볼 수 있다.
Unicode 15.1 Character Code Charts : https://www.unicode.org/charts/
Unicode 15.1 Character Code Charts
Unicode 15.1 Character Code Charts Scripts | Symbols & Punctuation | Name Index Find chart by hex code: Help Conventions Terms of Use Notational Systems Braille Patterns Musical Symbols Ancient Greek Musical Nota
www.unicode.org
Hangul Syllables : https://www.unicode.org/charts/PDF/UAC00.pdf

유니코드 문자 집합에서는 EUC-KR과 같이 완성형 인코딩 방식을 사용하고 있다. 위 표를 보면, "가"는 십육진수로 \( AC00_{(16)} \)으로 표현된다.
아스키 코드와 EUC-KR 인코딩 방식에서는 글자에 매칭되어 있는 코드를 인코딩 값으로 사용했지만, 유니코드는 UTF-8, UTF-16, UTF-32 등의 방식을 통해 인코딩하게 된다. 이 중에서 가장 많이 사용되는 방식은 UTF-8이다. 여기서 UTF는 Unicode Transformation Format의 약자로, 유니코드를 인코딩하는 방법을 의미한다.
UTF-8은 가변 길이 인코딩 방식으로, 일반적으로 1바이트에서 4바이트까지의 인코딩 결과를 만들어 낸다. (최대 6바이트까지 표현이 가능하지만 다른 인코딩 방식과 호환을 위해 4바이트까지만 사용한다.)

"가"를 유니코드에서 찾으면 U+AC00*이다. AC00은 0x0800 ~ 0xFFFF 사이에 위치하기 때문에 3바이트로 표현이 가능하다. \( AC00_{(16)} \)을 이진수로 바꾸면 \( 1010\ 1100\ 0000\ 0000_{(2)} \)가 되며, 이를 UTF-8 방식으로 인코딩하면 \( 11101010\ 10110000\ 10000000_{(2)} \)이 된다.
* 유니코드 글자에 부여된 값 앞에 U+를 붙여서 사용하기도 하는데, 이는 십육진수로 유니코드를 표현할 때 사용하는 표기 방식이다.
요약
- 문자 집합은 컴퓨터가 이해할 수 있는 문자의 모음을 의미하며, 문자 집합에 속한 문자들을 인코딩하여 0과 1로 표현할 수 있다.
- 아스키 문자 집합은 총 128개의 문자가 포함되어 있으며, 0부터 127까지 숫자가 각 문자에 할당되어 아스키 코드로 인코딩된다.
- EUC-KR은 한글을 표현할 수 있는 대표적인 완성형 인코딩 방식이며, 하나의 글자는 2바이트의 크기를 갖는다.
- 유니코드는 여러 나라의 문자를 포함하고 있는 문자 집합이며, 별도의 인코딩 방식을 통해 인코딩할 수 있다. 가장 대표적인 인코딩 방식으로는 UTF-8이 있다.
Reference
1. 혼자 공부하는 컴퓨터구조 + 운영체제 / 출판사: 한빛미디어 / 저자: 강민철
혼자 공부하는 컴퓨터 구조+운영체제 | 강민철 - 교보문고
혼자 공부하는 컴퓨터 구조+운영체제 | 혼자 해도 충분합니다! 1:1 과외하듯 배우는 IT 지식 입문서 42명의 베타리더 검증으로, ‘함께 만든’ 입문자 맞춤형 도서이 책은 독학으로 컴퓨터 구조와
product.kyobobook.co.kr
'Computer Science > 컴퓨터구조' 카테고리의 다른 글
| CS | 컴퓨터구조 | 고급 언어와 저급 언어 (0) | 2024.04.17 |
|---|---|
| CS | 컴퓨터 구조 | 정보 단위와 숫자 표현 (with. 이진수, 십육진수) (1) | 2024.03.28 |
| CS | 컴퓨터 구조 | 컴퓨터가 이해하는 정보와 컴퓨터의 핵심 부품 (0) | 2024.03.22 |