
이 글은 파이썬 라이브러리 중 데이터를 다룰 때 사용하는 pandas 라이브러리를 이용하여 엑셀(.xlsx), csv(.csv), 텍스트(.txt) 파일을 불러오는 방법에 대해 정리한 글이다.
pandas 라이브러리
pandas 라이브러리는 데이터 조작 및 분석을 위해 파이썬에서 사용할 수 있는 라이브러리이다. 파이썬에 기본적으로 포함되어 있는 라이브러리는 아니기 때문에 별도의 설치가 필요하다.
설치는 pip install pandas 명령어를 이용하여 설치할 수 있다.
pip install pandas
pandas 라이브러리를 파이썬 코드에서 사용하기 위해서는 import 작업이 필요하며, import는 일반적으로 아래와 같이 사용한다.
import pandas as pdpandas 라이브러리를 이용하면 다양한 파일 형식(.csv, .json, .xlsx, .txt 등)에서 데이터를 가져와 각종 데이터 처리를 진행할 수 있다.
쉼표로 구분된 값 파일(.csv) 불러오기
먼저 쉼표로 구분된 값 파일로 이루어져 있는 데이터를 불러오는 방법에 대해 알아보자. 쉼표로 구분된 값 파일이라 하면 이게 뭔가 싶을 수 있지만, 흔히 csv 파일이라고 부르는 파일이 바로 쉼표로 구분된 값 파일이다. 파일의 확장자는 .csv로 이루어져 있다.
csv 파일로 이루어진 데이터를 불러오는 가장 기본적인 방법은 다음과 같다.
import pandas as pd
path = "./test.csv"
df = pd.read_csv(path)path: 파일의 경로를 저장하는 변수df: 파일을 불러와 데이터프레임의 형태로 저장할 변수pd.read_csv: csv 파일을 불러올 때 사용하는 pandas의 함수
csv 파일을 데이터프레임으로 불러올 때 사용하는 함수는 pd.read_csv 이다. pd.read_csv 함수는 파일 경로에 해당하는 파라미터(filepath_or_buffer)를 필수로 입력받는다. (위 코드에서는 path 변수가 경로에 해당, 변수가 아닌 직접 경로를 입력하는 것도 가능)
필수 파라미터인 파일 경로 이외에 많이 사용하는 파라미터는 아래와 같다. (이후 정리할 텍스트 파일이나 엑셀 파일을 불러올 때도 많이 사용하는 파라미터이니 알아두자.)
sep: separate의 약자로 해당 데이터가 어떤 문자열로 분리되었는지 입력받는 파라미터. 기본값은sep=',".header: 컬럼 명에 해당하는 행을 선택하는 파라미터. 기본값은header=0으로 되어 있으며, 이는 데이터의 첫번 째 행을 컬럼 명으로 사용한다는 의미. 만약 파일을 중간부터 불러왔다면, 데이터 역시 중간부터 이루어져 있기 때문에header=None으로 설정 후 별도의 컬럼 명을 세팅해줘야 함.index_col: 인덱스로 사용할 컬럼을 선택하는 파라미터. 기본 값은index_col=False로 되어 있으며, 자동으로 인덱스를 0부터 생성함.index_col의 값으로 컬럼명 혹은 컬럼의 인덱스를 사용할 수 있음.skiprows: 원본 데이터 파일에서 몇 개의 행을 제외하고 데이터를 불러올지 결정하는 파라미터. 기본값은skiprows=0이며, 이는 파일의 첫번째 행부터 모두 불러온다는 의미. 원본 파일에서 위에서부터 몇 개의 행이 데이터가 아닌 다른 정보로 이루어져 있을 때 유용하게 사용됨.skipfooter:skiprows가 위에서부터 행을 제외하고 불러왔다면,skipfooter는 파일 아래에서부터 몇 개의 행을 제외하고 불러올 때 사용하는 파라미터. 기본값은skipfooter=0.
위 파라미터들을 이용해서 csv 파일을 불러오면 다음과 같이 파일의 데이터를 불러올 수 있다.
import pandas as pd
path = "./test.csv"
df = pd.read_csv(path, sep=',', header=0, index_col=0, skiprows=3, skipfooter=1)
텍스트 파일(.txt) 불러오기
텍스트 파일로 이루어져 있는 데이터는 .txt라는 확장자를 가지고 있으며, 메모장을 통해 열어볼 수 있는 파일 형식이다. 일반적으로 탭으로 구분되어 있는 경우가 많으며, 쉼표(,), 바(|) 등을 통해 구분되어 있다.
텍스트 파일로 이루어진 데이터를 불러오는 방법은 다음과 같다.
import pandas as pd
path = "./test.txt"
df = pd.read_csv(path)텍스트 파일도 csv 파일과 동일하게 pd.read_csv 함수를 이용하여 불러올 수 있다. 다만 텍스트 파일의 경우 구분자가 쉼표(,)가 아니라 탭으로 이루어져 있는 경우가 많다. 이 때는 구분자를 의미하는 sep 파라미터에 '\t'를 전달 인자로 넣어줘야 한다.
import pandas as pd
path = "./test.txt"
df = pd.read_csv(path, sep='\t', skiprows=3, skipfooter=1)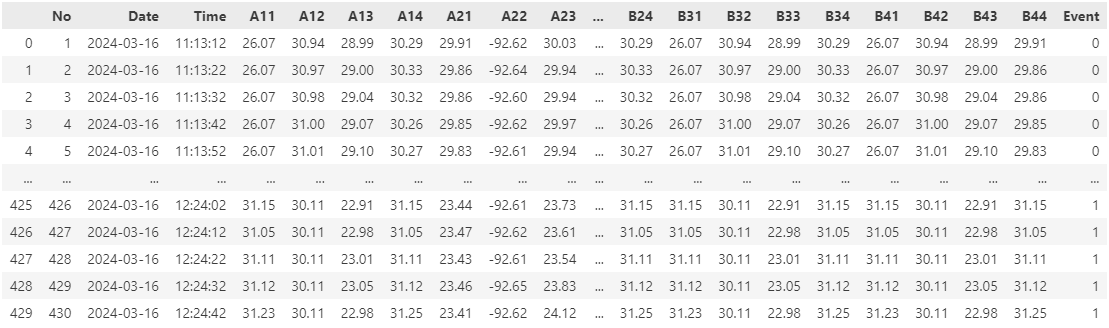
엑셀(.xlsx) 파일 불러오기
일반적으로 가장 많이 볼 수 있는 데이터는 엑셀로 정리된 데이터일 것이다. 엑셀 파일의 경우 .xlsx의 확장자를 사용한다.
엑셀 파일로 정리된 데이터는 다음과 같이 불러올 수 있다.
import pandas as pd
path = "./test.xlsx"
df = pd.read_excel(path)엑셀 파일은 pd.read_excel 함수를 이용하여 데이터프레임으로 불러올 수 있다. 하지만 파이썬를 이용하여 엑셀 파일을 불러온 적이 없다면, 그리고 별도의 라이브러리를 설치한 적이 없다면 아래와 같은 오류를 만날 수 있다.
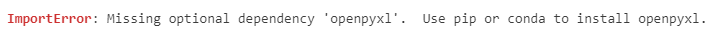
파이썬을 통해 엑셀 파일을 불러올 때는 openpyxl 이라는 라이브러리가 필요하다. 아래 명령어를 통해 openpyxl을 설치할 수 있다.
# pip를 이용한 설치
pip install openpyxl
# conda를 이용한 설치
conda install openpyxl설치한 후에는 정상적으로 엑셀 파일을 데이터프레임으로 불러올 수 있다.
import pandas as pd
path = "./test.xlsx"
df = pd.read_excel(path, skiprows=4, skipfooter=1)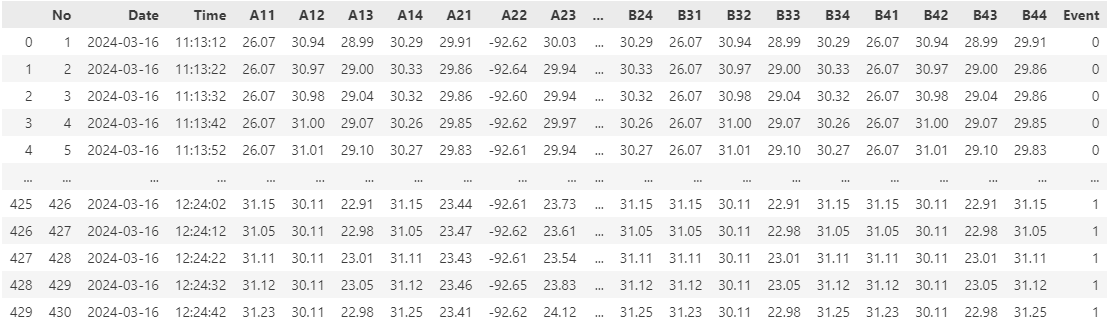
요약
- csv 파일과 텍스트 파일은
pd.read_csv함수를 이용하여 불러올 수 있다. 단, 텍스트 파일의 경우 구분자에 따라sep파라미터를 사용해야 한다. - 엑셀 파일은
pd.read_excel함수를 이용하여 불러올 수 있다. 단, openpyxl 라이브러리가 설치되어야 한다.
'Data Science > pandas' 카테고리의 다른 글
| 파이썬 | pandas | 데이터프레임의 전체 열(Column) 이름 가져오기 (1) | 2024.04.16 |
|---|---|
| 파이썬 | pandas | 데이터프레임을 엑셀 파일로 저장하기 (with. csv & xlsx) (0) | 2024.04.04 |
| 파이썬 | pandas | replace 함수를 이용해 데이터프레임의 값 변경하기 (0) | 2024.03.26 |
| 파이썬 | pandas | 한글이 있는 csv 파일 불러올 때 발생하는 UnicodeDecodeError 해결 (0) | 2024.03.24 |
| 파이썬 | pandas | 데이터 중 필요한 열(Column)만 추출하기 (0) | 2024.03.18 |