
이 글에서는 기술통계에서 사용되는 대표값과 산포도에 대해 알아보고, 기술통계량을 어떻게 제시하는 것이 좋은지 알아본다.
기술통계량
기술통계량은 자료의 특성을 표현하는 값으로, 대표값과 산포도가 있다.
대표값
대표값(measure of central tendency)은 자료를 잘 표현할 수 있는 수, 이름 그대로 전체 자료를 대표할 수 있는 값을 의미한다. 대표값에는 (산술)평균, 중위수, 최빈치 등이 있는데, 이 중에서 (산술)평균이 가장 많이 사용된다.
각 대표값에 대해 각각 살펴보면 다음과 같다.
(산술)평균 (arithmetic mean)
모집단으로부터 추출한 표본(sample)의 관찰치( \( X \) )가 \( x_1, x_2, x_3, \cdots , x_n \)일 때, 이 표본의 평균( \( \overline X \) )은 아래의 식으로 계산할 수 있다.
\[ \overline X = {\sum_{i=1}^n x_i \over n} \]
평균은 대표값으로 가장 많이 사용되지만, 평균은 극단치에 민감하기 때문에 이상치(outlier)가 있는 경우 평균의 오류가 발생할 수 있다. 이러한 자료의 경우, 평균을 대표값으로 사용하기에 부적절할 수 있다.
- 자료 1 : 3, 5, 7, 6, 7, 8, 10
- \( \overline X = {\sum_{i=1}^n x_i \over n} = {3+5+7+6+7+8+10 \over 7} = 6.57 \)
- 자료 2 : 3, 5, 7, 6, 7, 8, 100
- \( \overline X = {\sum_{i=1}^n x_i \over n} = {3+5+7+6+7+8+100 \over 7} = 19.43 \) → 19.43 이라는 값이 위 자료를 대표할 수 있는 값인가는 의문이 발생함 (평균의 오류)
모집단에서 여러 표본을 추출한 후, 각 표본의 평균을 모아 평균을 계산하면, 즉 표본평균의 평균( \( E(\overline X) \) )은 모평균( \( \mu \) )과 같아진다.
중위수 (median)
중위수(혹은 중앙값)는 자료를 크기 순으로 나열했을 때, 중앙에 위치한 값을 의미한다. 자료의 개수를 \( n \)이라고 할 때, \( n \)이 홀수이면 \( n+1 \over 2 \)번째 위치한 값이 중위수가 되며, \( n \)이 짝수이면 \( n \over 2 \)번째 값과 \( {n \over 2} + 1 \)번째 값의 산술평균이 중위수가 된다. \( n \)이 짝수인 경우 중위수는 자료에 없는 값이 될 수도 있다.
대부분 대표값으로 평균을 사용하지만, 각 표본의 차이가 매우 커 평균이 의미가 없고 순위(백분위)가 더 중요할 때 중위수를 대표값으로 사용한다.
- 자료 2 : 3, 5, 7, 6, 7, 8, 100
- 위 자료의 경우 평균은 19.43, 중위수는 7이다. 자료 2와 같은 경우 중위수가 평균보다 자료를 대표하기에 적절한 값이기 때문에 대표값으로 중위수를 사용한다.
최빈치 (mode)
최빈치(혹은 최빈값)는 자료에서 가장 많이 나오는 값을 의미한다. 최빈치는 각 값의 수치적 평균값이 의미가 없고, 대소 관계가 없는 경우 사용한다. 양적 자료에서는 거의 사용되지 않으며, 주로 질적 자료의 대표값을 선정하는 경우 사용한다. 평균이나 중위수는 단 하나의 값이 대표값으로 사용되지만, 최빈치는 빈도가 가장 많은 값이 여러 개인 경우 모든 값이 최빈치가 된다. 즉, 여러 개의 값을 가질 수 있다.
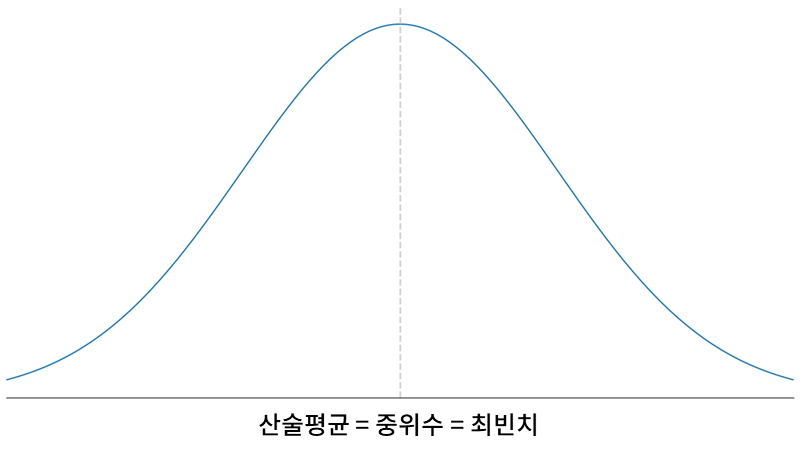
표본의 분포가 대칭적이면 산술평균, 중위수, 최빈치는 모두 같은 값을 가진다.
산포도
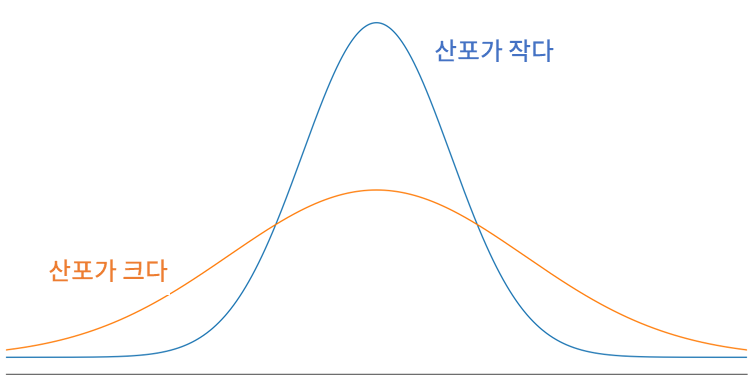
산포도(measure of dispersion)는 자료가 흩어져 있는 정도를 하나의 수로 나타낸 값을 의미한다. 분산, 표준편차, 범위, 사분위 범위 등이 산포도에 포함된다. 자료가 중앙에 모여있으면 "산포가 작다"고 표현하며, 자료가 넓게 펴져있으면 "산포가 크다"고 표현한다.
각 산포도에 대해 살펴보면 다음과 같다.
분산과 표준편차
분산(variance)과 표준편차(standard deviation; SD)는 자료(각 관찰치)가 평균으로부터 얼마나 흩어져 있는지 표현하는 값이다. 표준편차와 분산은 제곱근 관계를 가지고 있다. 분산(표본분산)은 아래의 식으로 계산할 수 있다.
\[ s^2 = {\sum_{i=1}^{n}{(x_i - \overline X)^2} \over {n-1}} \ \ \ \ \ \left( \text{cf, 모분산 : } \ \sigma^2 = {\sum_{i=1}^{N}{(x_i - \mu)^2} \over {N}} \right) \]
이때 분산(표본분산)을 계산할 때 \( n \)이 아닌 \( n-1 \)로 나누는 이유는 \( n-1 \)로 나누는 것이 모분산과 더 비슷한 값이 나오기 때문이다.
분산은 제곱의 형태를 가지기 때문에 실제보다 값이 크게 표현되며, 관찰치 본래 단위의 의미를 갖지 않게 된다. 따라서 본래 단위로 표현하기 위해서는 분산에 제곱근을 씌운 표준편차를 사용한다. 표준편차(표본 표준편차)는 아래의 분산에 루트를 씌워 계산할 수 있다.
\[ s = \sqrt {s^2} \ \ \ \ \ \left( \text{cf, 모표준편차 : } \ \sigma = \sqrt{\sigma^2} \right) \]
범위와 사분위 범위
분산과 표준편차가 대표값 중 평균과 관련이 있는 산포도였다면, 범위(range)와 사분위 범위(inter-quartile range; IQR)는 대표값 중 중위수와 관련이 있는 산포도이다. 범위와 사분위 범위는 이름에서 알 수 있듯이, 자료가 최소치부터 최대치까지 얼마나 넓게 분포하고 있는지 나타내는 값이다.
범위는 \( \text{max} - \text{min} \) 으로 계산할 수 있다. 쉽게 계산할 수 있지만, 자료의 크기에 영향을 받으며 특히 극단치에 영향을 많이 받는다. 극단치의 영향을 줄이기 위해 사분위 범위를 사용하기도 한다.
사분위수(quartile)는 자료를 4등분 하는 3개의 수를 의미한다.
- 1사분위수(Q1) : 25% 순위에 위치한 값
- 2사분위수(Q2) : 50% 순위에 위치한 값 (= 중위수)
- 3사분위수(Q3) : 75% 순위에 위치한 값
사분위 범위는 사분위수 중에서 \( Q3 - Q1 \) 으로 계산할 수 있다. 사분위 범위는 극단치의 영향을 받지 않고, 자료의 크기에 영향을 받지 않는 장점이 있다. 하지만 자료의 크기가 작으면 계산하기 어렵다.
상대적인 산포도 비교
측정단위가 서로 다른 자료의 상대적인 산포도를 비교하고자 할 때에는 변동계수(coefficient of variation; CV)를 이용한다. 변동계수는 변이계수라고도 하며, 변동계수는 다음과 같이 계산할 수 있다.
\[ CV = {s \over {\overline X}} \times 100 \text{ (%)} \]
변동계수의 값이 클수록 상대적인 산포도가 크다는 것을 의미하며, 변동계수는 % 단위를 갖는다.
기술통계량 제시 방법
기술통계량을 제시할 때는 항상 대표값과 산포도를 동시에 제시해야 한다. 대표값과 산포도는 적절한 조합이 존재한다. 평균은 항상 표준편차와 함께 제시하며, 중위수는 범위 혹은 사분위범위와 함께 제시해야 한다.
- 평균과 표준편차 제시
- \( \text{mean} \pm \text{SD} \) → ex) \( 36.5 \pm 1.9 \)
- 중위수와 범위 혹은 중위수와 사분위수 제시
- \( \text{median(range)} \) or \( \text{median(IQR)} \) → ex) \( 45(18 \text{ ~ } 67) \)
평균과 범위(혹은 사분위범위)를 제시하거나 중위수와 표준편차를 제시하는 것은 적절하지 않다. 또한 평균과 표준오차(standard error; SE)를 제시하는 경우도 종종 볼 수 있는데, 표준오차는 표본평균의 표준편차로서 산포도를 측정하는 개념이 아니라 추정치의 정밀도(precision)를 나타내는 값이기 때문에 적절하지 않다.
'Data Science > 통계학' 카테고리의 다른 글
| 통계학 | 이산형 확률 분포와 연속형 확률 분포 간단 정리 (1) | 2024.01.24 |
|---|---|
| 통계학 | 확률과 베이즈 정리(Bayes' rule) (1) | 2024.01.21 |
| 통계학 | 통계학적 자료와 변수의 구분 (0) | 2024.01.05 |
| 통계학 | 모집단과 표본 및 통계학적 기술과 추론 (0) | 2024.01.05 |