
이 글에서는 확률의 기본 내용에 대해 정리하고, 사전 확률을 이용하여 사후 확률을 계산하는 베이즈 정리(Bayes' rule)에 대해 알아본다.
확률
용어 정리
먼저 확률에서 사용되는 용어에 대해 정리한다.
- 확률 실험 (random experience)
- 확률 실험은 실행 이전에 그 결과를 정확하게(100%) 예측할 수 없는 실험을 의미한다. 만약 연구자가 하고자 하는 연구가 확률 실험이 아니라면, 통계학을 적용할 수 없다.
- 확률 실험은 동일한 조건으로 실험을 반복하더라도 그 실험의 결과가 동일하지 않고 임의의 형태로 나타난다는 특징이 있다.
- 동전 던지기, 주사위 굴리기 등이 확률 실험에 포함된다.
- 표본 공간 (sample space)
- 표본 공간은 확률 실험을 통해 얻어지는 가능한 모든 결과들의 집합을 의미한다. 주로 대문자 \( \text{S} \) 혹은 \( \Omega \)로 표기한다.
- 동전 던지기의 표본 공간은 \( \text{S} = \{\text{front, back}\} \)이며, 주사위 굴리기의 표본 공간은 \( \text{S} = \{1, 2, 3, 4, 5, 6\} \)이다.
- 사건 (event)
- 사건은 확률 실험을 통해 얻어진 실험 결과들 중, 관심있는 실험 결과들의 집합을 의미한다. 즉, 사건은 표본 공간의 부분집합이 된다. 주로 알파벳 대문자(A, B, C, ...)를 사용하여 표기한다.
- 확률 (probability)
- 특정 사건이 다른 사건에 비해 상대적으로 일어날 가능성을 의미한다. 상대도수 개념을 이용하여 사건 \( \text{A} \)가 발생할 확률은 \( P(A) \)로 표기하고, 다음과 같이 계산할 수 있다.
\[ P(A) = {\text{사건 A의 경우의 수} \over \text{전체(표본 공간) 경우의 수}} \]
- 특정 사건이 다른 사건에 비해 상대적으로 일어날 가능성을 의미한다. 상대도수 개념을 이용하여 사건 \( \text{A} \)가 발생할 확률은 \( P(A) \)로 표기하고, 다음과 같이 계산할 수 있다.
확률의 공리
공리(axiom)는 논리학이나 수학 등의 이론체계에서 가장 기초적인 근거가 되는 명제를 의미한다. 증명할 필요 없이 자명한 진리이자, 다른 명제들을 증명하는 데 전제가 되는 원리로서 가장 기본적인 가정을 가리킨다.
확률의 공리는 아래와 같다.
- 전체 표본의 확률은 항상 1이다. 즉, \( P(S) = 1 \)이다.
- 특정한 사건 A에 대해서 \( P(A) \)는 0이상, 1이하의 값으로 나타난다.. 즉, \( 0 \le P(A) \le 1 \)이다.
- 두 사건 A와 B가 동시에 일어날 수 없을 때(상호 배타적 집합일 때), \( P(A \cup B) = P(A) + P(B) \)이다.
- 사건 A가 발생하면 사건 B가 발생할 수 없을 때, 이 두 사건을 상호배타적이라고 한다. 두 사건이 상호배타적이면 공통으로 가지고 있는 표본이 하나도 없다. 즉, 두 사건이 상호배타적이면 \( P(A \cap B) = 0 \)이다.
확률의 기본 성질
확률은 아래와 같은 기본 성질을 갖는다.
- 사건 A와 사건 B가 동시에 일어날 확률은 \( P(A \cup B) = P(A) + P(B) - P(A \cap B) \)로 나타낼 수 있다.
- 사건 A의 여사건 \( A^c \)이 나타날 확률은 \( P(A^c) = P(\overline A) = 1 - P(A) \)로 나타낼 수 있다.
- 사건 A가 사건 B의 부분집합이라면, 사건 A의 확률 \( P(A) \)와 사건 B의 확률 \( P(B) \)은 \( P(A) \le P(B) \)의 관계를 가진다.
조건부 확률
조건부 확률(conditional probability)이란 어떤 사건이 일어났을 때, 다른 사건이 일어날 확률을 의미한다. 즉, 사건 A가 일어났을 때, 사건 B가 일어날 확률을 의미하는 것이다.
사건 A가 일어났을 때 사건 B가 일어날 확률은 \( P(B \vert A) \)로 표현한다. \( P(B \vert A) \)는 다음과 같이 계산할 수 있다. (단, \( P(A) > 0 \)이다.)
\[ P(A \vert B) = {P(B \cup A) \over P(A)} \]
이때, 사건 A와 사건 B가 서로 독립(independent) 사건이면, \( P(A \vert B) = P(B) \)가 된다. (사건 A와 사건 B가 서로 독립 사건이면 \( P(A \cap B) = P(A) \times P(B) \)로 나타낼 수 있기 때문이다.)
베이즈 정리
베이즈 정리(Bayes' rule)는 두 확률 변수의 사전 확률과 사후 확률 사이의 관계를 나타내는 정리이다. 베이즈 정리를 이용하여 사전 확률을 알고 있을 때, 사전 확률을 이용하여 사후 확률을 구할 수 있다. 임상 실험 등에서 확률을 계산할 때 사용하게 된다.
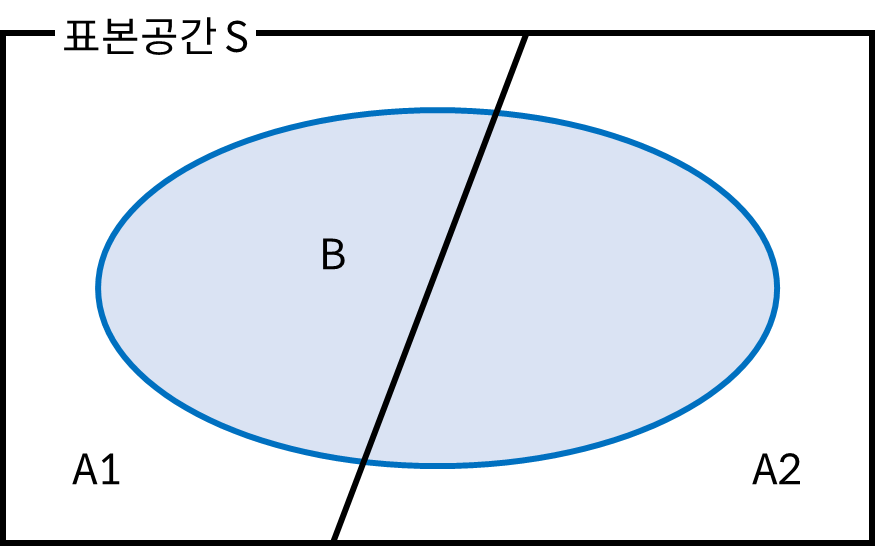
사건 \( A_1 \)과 사건 \( A_2 \)가 표본 공간 \( S \)의 부분집합이며, 서로 상호배타적 관계에 있다고 가정하고, 사건 \( B \)가 위 그림에서와 같이 사건 \( A_1 \)과 사건 \( A_2 \)의 일부분을 차지하고 있으면 \( P(B) \)는 다음과 같이 조건부 확률의 합으로 표현할 수 있다.
\[ \begin{align} P(B) &= P(A_1 \cap B) + P(A_2 \cap B) \\
&= P(A_1)P(B \vert A_1) + P(A_2)P(B|A_2) \end{align} \]
이렇게 관심이 있는 사건 B의 확률 \( P(B) \)를 조건부 확률의 합으로 표현하는 것을 전확률 법칙(law of total probability)라고 하며, 베이즈 정리의 시작이 된다.
\( P(B \vert A_1) \)과 \( P(B \vert A_2) \)는 구하기 쉽기 때문에 베이즈 정리를 이용하여 \( P(A_1 \vert B) \)나 \( P(A_2 \vert B) \)를 구하는 것이다. 베이즈 정리는 앞에서 언급했듯이, 사전 확률을 알고 있을 때 사후 확률을 계산하는 것으로, 이때 사전 확률(prior probability)은 \( P(A_1) \), \( P(A_2) \)이고, 사전정보 조건부확률(data probability)은 \( P(B \vert A_1) \), \( P(B \vert A_2) \)이 되며, 베이즈 정리를 이용하여 구하는 사후 확률(posterior probability)은 \( P(A_1 \vert B) \)와 \( P(A_2 \vert B) \)이 된다.
베이즈 정리를 이용한 \( P(A_1 \vert B \)의 계산은 다음과 같다.
\[ \begin{align} P(A_1 \vert B) &= {P(A_1)P(B \vert A_1) \over P(B)} \\
&= {P(A_1)P(B \vert A_1) \over P(A_1)P(B \vert A_1) + P(A_2)P(B \vert A_2)} \end{align} \]
진단 검사 (screening test)
진단 검사를 예시로 베이즈 정리에 대해 정리해보고자 한다. 먼저 진단 검사에서 알아야 하는 용어들에 정리하면 다음과 같다.
| 진단 \ 질병 | 질병 보유 ( \( D^+ \) ) | 질병 미보유 ( \( D^- \) ) | 합계 |
| 검사결과 양성 ( \( T^+ \) ) | a | b | a + b |
| 검사결과 음성 ( \( T^- \) ) | c | d | c + d |
| 합계 | a + c | b + d | a + b + c + d |
- 민감도(sensitivity)
- 질병을 가지고 있는 사람이 진단에서 양성의 결과를 얻을 확률 : \( P(T^+ \vert D^+) = {a \over a+c} \)
- 특이도(specificity)
- 질병을 가지고 있지 않은 사람이 진단에서 음성의 결과를 얻을 확률 : \( P(T^- \vert D^-) = {d \over b+d} \)
- 양성예측도 (positive predictive value : PPV)
- 진단결과 양성인 사람이 실제로 질병을 가지고 있을 확률 : \( P(D^+ \vert T^+) = {a \over a+b} \)
- 음성예측도 (negative predictive value : NPV)
- 진단결과 음성인 사람이 실제로 질병을 가지고 있지 않을 확률 : \( P(D^- \vert T^-) = {d \over c+d} \)
이때, 진단검사에서 베이즈 정리는 양성예측도(PPV)를 계산하기 위해 사용된다. 양성예측도는 다음의 식을 이용해서 계산할 수 있다.
\[ \text{PPV} = {\text{prevalence} \times \text{sensitivity} \over \text{prevalence} \times \text{sensitivity} + (1 - \text{prevalence}) \times (1 - \text{specificity)})} \]
이를 확률식으로 표현하면 다음과 같다.
\[ \begin{align} P(D^+ \vert T^+) &= {P(D^+ \cap T^+) \over P(T^+)} \\
&= {P(T^+ \vert D^+)P(D^+) \over P(T^+ \vert D^+)P(D^+) + P(T^+ \vert D^-)P(D^-)} \end{align} \]
여기서 유병률(prevalence)는 각 질병이 발병할 확률로서 이미 알려진 값이며, 진단 검사 키트의 민감도와 특이도 역시 검사 키트의 성능 지표로서 알려진 값이기 때문에, 이들을 이용하여 양성예측도를 계산할 수 있다.
'Data Science > 통계학' 카테고리의 다른 글
| 통계학 | 이산형 확률 분포와 연속형 확률 분포 간단 정리 (1) | 2024.01.24 |
|---|---|
| 통계학 | 기술통계량 : 대표값과 산포도 (0) | 2024.01.06 |
| 통계학 | 통계학적 자료와 변수의 구분 (0) | 2024.01.05 |
| 통계학 | 모집단과 표본 및 통계학적 기술과 추론 (0) | 2024.01.05 |