
이 글에서는 이산형 확률 분포(이항 분포, 포아송 분포)와 연속형 확률 분포(정규분포, 표준정규분포)에 대해 빠르게 알아보는 글이다. 공식에 대한 유도나 증명 과정은 생략한다.
이산형 확률 분포
이산형 확률 분포(discrete probability distribution)는 이산형 확률 변수(discrete random variable)에 대한 확률 분포를 의미한다. 여기서 이산형(discrete)이란 대소 비교의 의미가 있는, 셀 수 있는 정수 자료형을 의미한다. 예를 들면 자녀 수, 사고 횟수, 제품의 개수 등이 이산형 확률 변수에 속한다.

이산형 변수 \( X \)의 모든 실현 가능한 실현치 \( x_1, x_2, \cdots \)에 대해 확률 질량(확률) \( f(x_1) = P(X = x_1), f(x_2) = P(X = x_2), \cdots \)가 대응될 때, 변수 \( X \)를 이산형 확률 변수라 하고, \( f(x_1), f(x_2), \cdots \)를 이산형 확률 분포라고 한다. 함수 \( f(x) \)를 확률질량함수(probability mass function)라고 한다.
이항 분포
이항 분포(binomial distribution)는 연속된 \( n \)번의 독립적 시행에서 각 시행이 확률 \( p \)를 가질 때의 이산 확률 분포를 의미한다. 이항 분포는 베르누이 실험(Bernoulli trial)과 관련있는데, 베르누이 실험은 동전 던지기와 같이 어떤 실험의 결과가 오직 두 가지 중의 하나로만 나타나는 실험이다. 즉, 이항 분포는 이러한 베르누이 실험을 독립적으로 \( n \)번 반복 할 때 관심 있는 사건이 발생하는 횟수(\( X \))에 대한 분포를 의미하는 것이다.
이항 분포는 다음과 같이 표기할 수 있다. 이때 \( n \)은 반복 시행 횟수, \( p \)는 관심있는 사건이 발생할 확률이다.
\[ X \sim B(n, p) \]
그리고 이항 분포의 확률질량함수는 다음과 같이 나타낼 수 있으며, 이때 확률 \( P(X = x) \)는 \( n \)번의 시행 중 사건이 \( x \)번 발생할 확률을 의미한다.
\[ P(X = x) = {n \choose x} p^x(1-p)^{n-x} = {}_nC_x \ p^x (1-p)^{n-k} \]
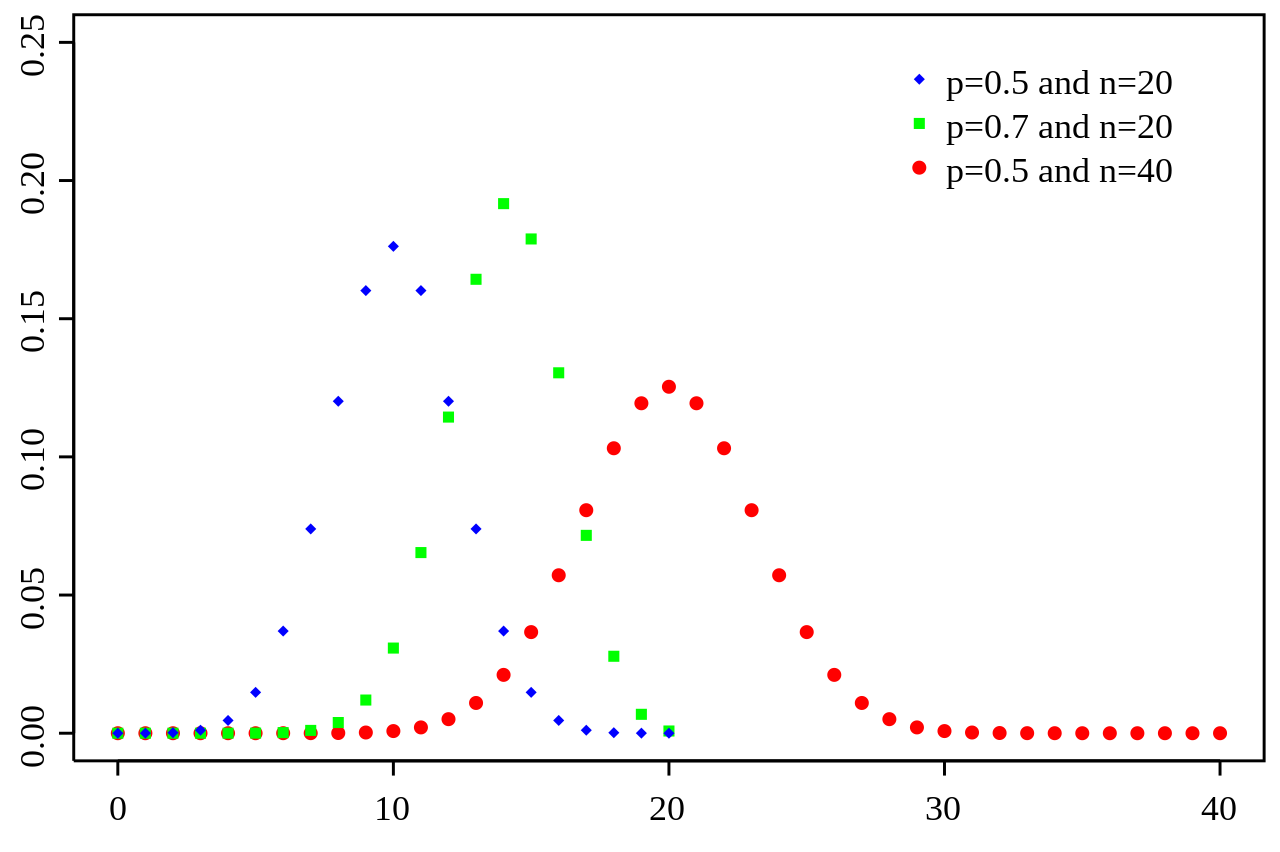
확률 변수 \( X \)가 이항 분포를 따를 때, 즉 \( X \sim B(n, p) \) 이면 평균는 \( E(X) = np \), 그리고 분산은 \( V(X) = np(1-p) \)로 나타낼 수 있다.
포아송 분포
포아송 분포(Poisson distribution)는 단위 시간(기간) 동안 특정 사건이 발생하는 횟수(\( X \))에 대한 분포를 의미한다. (표기에 따라 푸아송 분포라고 하기도 한다.)
단위 시간 동안 특정 사건이 발생하는 평균 발생 횟수(기댓값)가 \( \lambda \)라고 할 때, 포아송 분포는 다음과 같이 표기할 수 있다.
\[ X \sim P(\lambda) \]
확률 변수 \( X \)가 포아송 분포를 따를 때, 특정 사건이 \( x \)번 발생할 확률(확률질량함수)은 다음과 같이 나타낼 수 있다.
\[ P(X = x) = {e^{ - \lambda } \lambda^x \over x!} \]
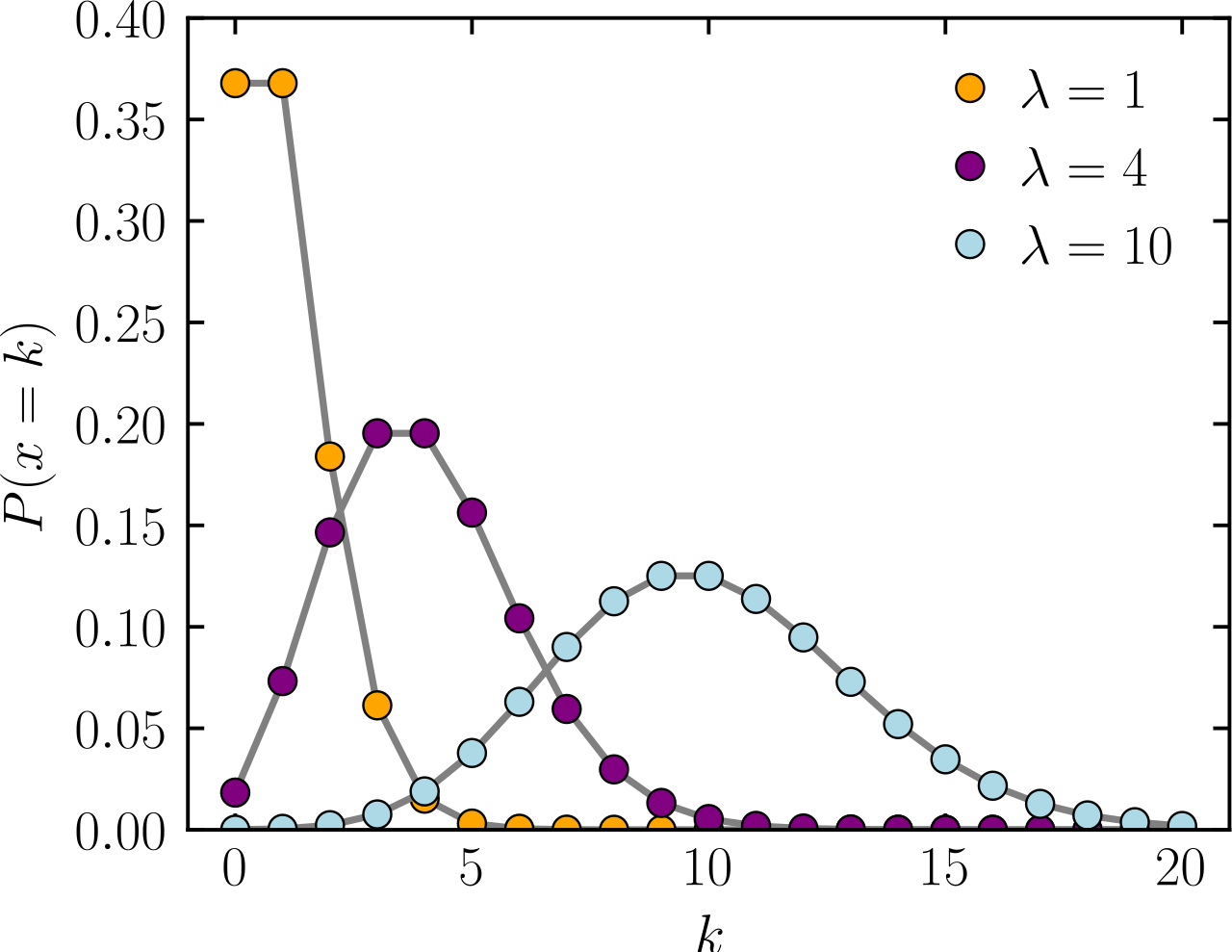
그리고 확률 변수 \( X \)가 포아송 분포를 따르면, 즉 \( X \sim P(\lambda) \)이면 평균(\( E(X) \))과 분산(\( V(X) \))은 모두 \( \lambda \)이다. (\( E(X) = V(X) = \lambda \)) 평균과 분산이 같은 것은 포아송 분포의 특징 중 하나이다.
이항 분포와 포아송 분포의 관계
포아송 분포는 이항 분포의 특수한 형태라고 할 수 있다. 이항 분포 (\( X \sim B(n, p) \))를 따르는 확률 변수 \( X \)에서 \( n \)이 충분히 커지고 \( p \)가 충분히 작은 경우(0에 가까운 경우), 근사적으로 확률 변수 \( X \)는 \( \lambda = np \)인 포아송 분포를 따르게 된다.
연속형 확률 분포
연속형 확률 분포(continuous probability distribution)는 연속형 확률 변수(continuous random variable)에 대한 확률 분포를 의미한다. 이때, 연속형 확률 변수는 이산형 확률 변수와 달리 확률 변수가 취할 수 있는 값이 무한하기 때문에 모든 값을 나열할 수는 없다. 연속형 확률 변수는 확률 변수 \( X \)가 임의의 특정값을 가질 확률은 항상 0이라는 특징을 가지고 있다. 따라서 연속형 확률 변수는 특정 값을 가질 확률을 구하는 것은 의미가 없고, 확률 변수의 범위(range)에 대한 확률을 계산한다.
확률 변수 \( X \)가 연속형 확률 변수일 때, \( X \)가 이루는 연속형 확률 분포를 함수 \( f(x) \)로 나타낸 것을 확률밀도함수(probability density function)라고 한다. 이때, 확률 변수 \( X \)는 연속형 확률 변수이기 때문에 특정 값에 대한 확률 \( P(X = x) \)을 나타내는 것이 아닌, 어떤 구간에 대한 확률 \( P(a \le X \le b) \)를 나타내게 된다. 확률밀도함수의 아래 면적이 연속형 확률 분포의 확률이 되기 때문에 확률 밀도 함수를 특정 구간에 대해 적분함으로써 확률을 구할 수 있다.
\[ P(a \le X \le b) = \int^b_a f(x) dx \]
그리고 확률밀도함수 \( f(x) \)의 아래 전체 면적은 항상 1이다.
\[ P(-\infty \le X \le \infty) = \int^{\infty}_{-\infty} f(x) dx = 1 \]
정규 분포
정규 분포(noraml distribution)는 연속형 확률 분포 중 가장 대표적인 확률 분포 중 하나이다. 중심극한정리(central limit theorem)에 의해 독립적인 확률 변수들의 평균은 정규 분포에 가까워지는 성질이 있기 때문에 수집된 자료의 분포를 근사하는데 자주 사용하게 된다. 그래서 모든 확률 분포들 중에서 가장 중요하고 일반적으로 가장 많이 사용되는 확률 분포이다.
확률 변수 \( X \)가 평균이 \( \mu \)이고 표준편차가 \( \sigma \)인 정규분포를 따를 때 정규분포는 다음과 같이 표기할 수 있다.
\[ X \sim N(\mu, \sigma^2) \]
정규 분포의 확률밀도함수 \( f(x) \)는 다음과 같이 나타낼 수 있다.
\[ f(x) = {1 \over \sqrt{2 \pi \sigma^2}} \text{exp}\left( -{(x - \mu)^2 \over 2 \sigma^2} \right) \]
이때, 정규 분포 \( N(\mu, \sigma) \)의 그래프 모양은 평균(\( \mu \))과 표준편차(\( \sigma \)) 2개의 매개 변수에 의해 모양이 결정된다.
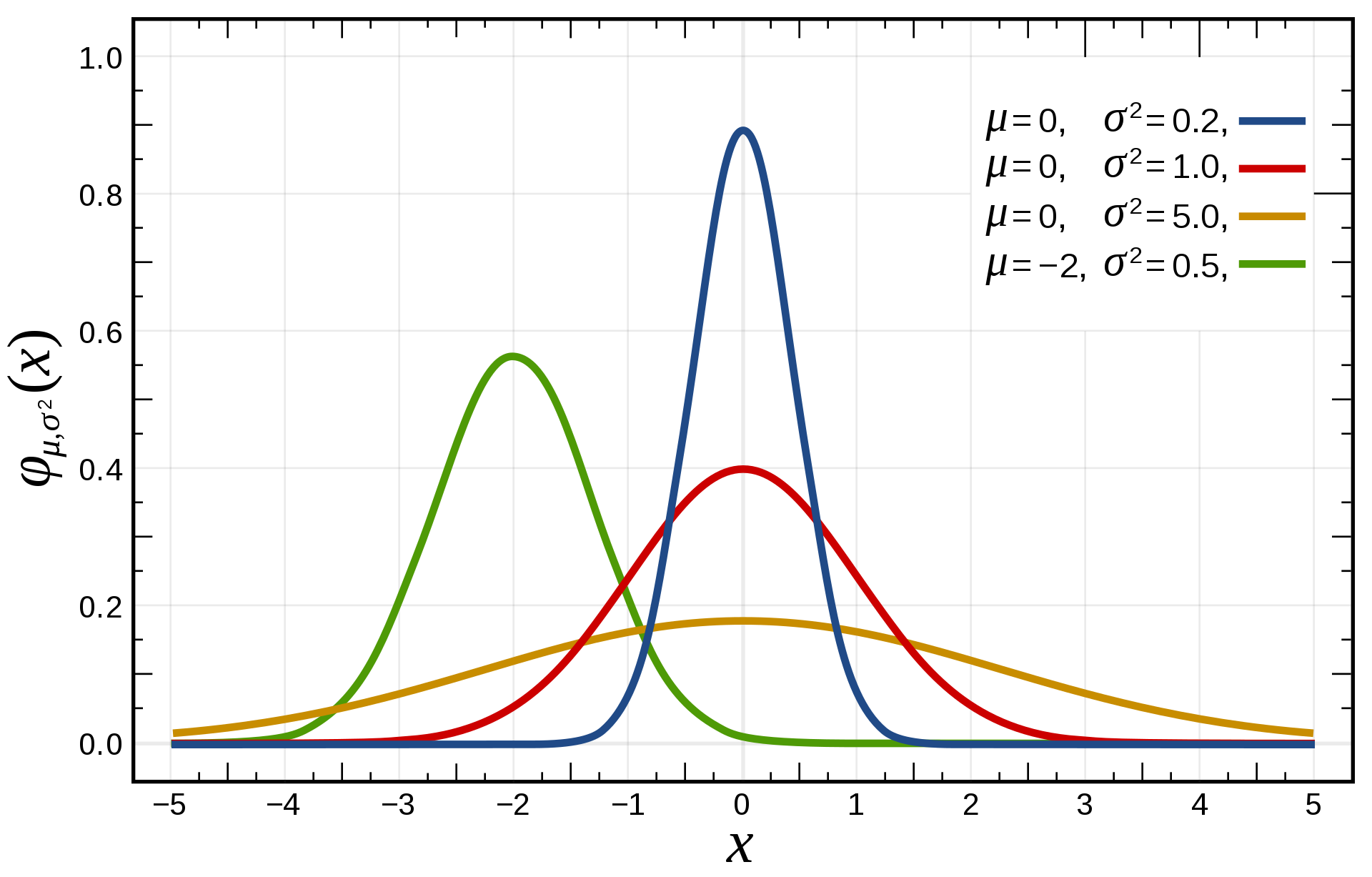
정규 분포는 평균과 표준편차에 의해 그래프 모양이 결정되기 때문에 표준편차가 일정하고 평균이 달라지면 대칭축이 이동하며, 평균이 일정하고 표준편차가 달라지면 그래프의 높이가 달라지게 된다. 표준편차가 커지면 그래프의 중앙이 낮아지고 좌우가 넓어지며, 표준편차가 작아지면 그래프의 중앙이 높아지고 좌우가 좁아지게 된다.

정규 분포는 다음과 같은 성질을 갖는다.
- 평균(\( \mu \))을 중심으로 종모양의 대칭적 형태를 이룬다.
- 정규 분포를 따르는 확률 변수 \( X \)의 평균, 중앙값, 최빈값은 모두 동일하다
- 정규 분포 그래프 아래 전체 면적은 1이다.
- 정규 분포 곡선은 꼬리 부분이 \( \pm \infty \)로 근접한다. (확률 변수 \( X \)가 \( \pm \infty \) 사이의 모든 값을 가진다.) → 점근적 특성(asymptotic property)
- 정규 분포의 위치는 평균 \( \mu \)에 의해서 결정되며, 정규 분포의 분포 형태는 표준편차 \( \sigma \)에 의해 결정된다.
표준 정규 분포
표준 정규 분포(standard normal distribution)는 정규 분포 중에서 평균이 0이고 표준편차가 1인 정규 분포를 의미한다. 확률 변수 \( X \)가 정규 분포를 따르면 표준 정규 분포로 정규화할 수 있다.
\[ \text{If } X \sim N(\mu, \sigma^2) \text{, then } Z = {X - \mu \over \sigma} ~ N(0, 1) \]
표준 정규 분포의 확률밀도함수 \( f(z) \)는 다음과 같이 표현된다.
\[ f(z) = {1 \over \sqrt{2 \pi}} \text{exp}\left( -{1 \over 2} z^2 \right) \]

정규 분포 근사
이항 분포의 정규 분포 근사
이항 분포를 따르는 확률 변수 \( X \)에서, 시행 횟수 \( n \)이 충분히 커지고, 확률 \( p \)가 0이나 1에 가깝지 않은 경우, 확률 변수 \( X \)는 정규 분포에 근사하게 된다. (일반적으로 \( np(1-p) \ge 5 \)이면 정규 분포에 근사하게 된다.)
이항 분포가 정규 분포에 근사하면, 확률 변수 \( X \)는 \( N(np, np(1-p)) \)인 정규 분포에 근사한다.
\[ X \sim B(n, p) \ \ \ \Longrightarrow \ \ \ X \sim N(np, np(1-p)) \]
이를 표준화시키면 표준 정규 분포에 근사하게 된다.
\[ Z = {X - \mu \over \sigma} = {X - np \over \sqrt{np(1-p)}} \sim N(0, 1) \]
포아송 분포의 정규 분포 근사
포아송 분포를 따르는 확률 변수 \( X \)에서, 평균 발생 횟수 \( \lambda \)가 충분히 커지면 확률 변수 \( X \)는 정규 분포에 근사하게 된다. (일반적으로 \( \lambda \ge 10 \)이면 정규 분포에 근사하게 된다.)
포아송 분포가 정규 분포에 근사하면, 확률 변수 \( X \)는 \( N(\lambda, \lambda) \)인 정규 분포에 근사한다.
\[ X \sim P(\lambda) \ \ \ \Longrightarrow \ \ \ X \sim N(\lambda, \lambda) \]
이를 표준화시키면 표준 정규 분포에 근사하게 된다.
\[ Z = {X - \mu \over \sigma} = {X - \lambda \over \sqrt{\lambda}} \sim N(0, 1) \]
'Data Science > 통계학' 카테고리의 다른 글
| 통계학 | 확률과 베이즈 정리(Bayes' rule) (1) | 2024.01.21 |
|---|---|
| 통계학 | 기술통계량 : 대표값과 산포도 (0) | 2024.01.06 |
| 통계학 | 통계학적 자료와 변수의 구분 (0) | 2024.01.05 |
| 통계학 | 모집단과 표본 및 통계학적 기술과 추론 (0) | 2024.01.05 |