
이 글에서는 통계학적 자료에 대해 알아보고, 통계학적 자료를 구성하는 변수들을 측정 수준에 따라 구분하는 방법에 대해 알아본다.
통계학적 자료
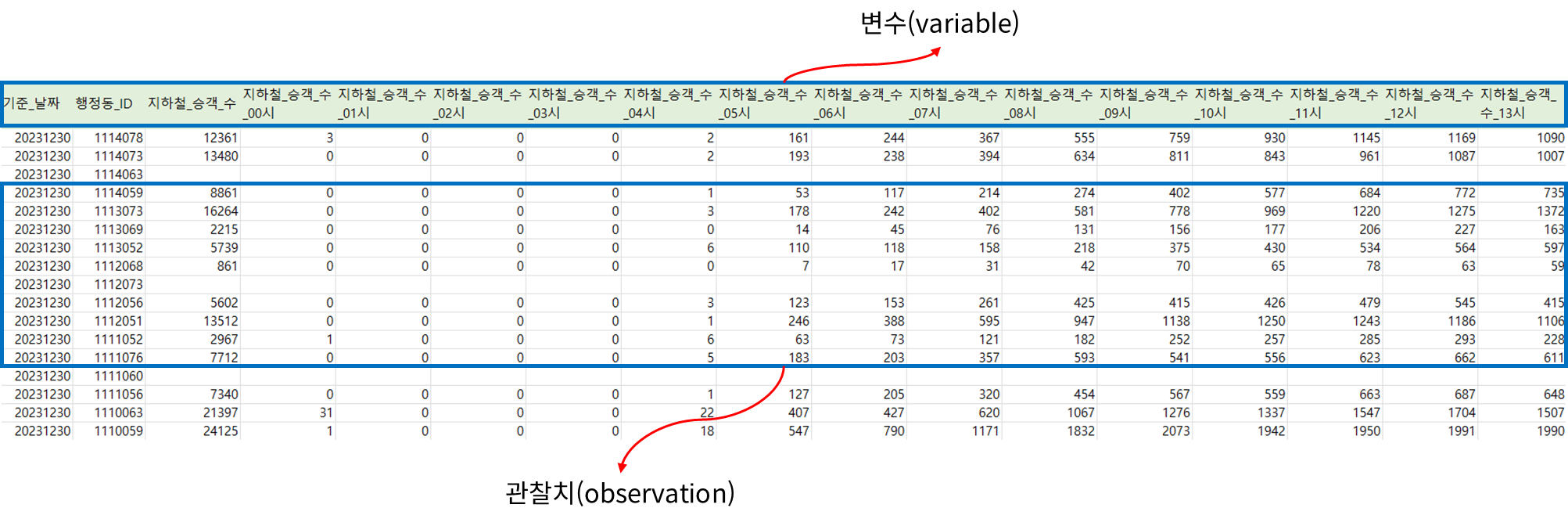
통계학적 자료는 위 이미지와 같이 실험, 설문조사 등 다양한 방법을 통해 모아진 데이터(raw data)를 의미하며, (확률)변수(variable)와 관찰치(observation)로 구성되어 있다. 가장 상단에 열(column)의 이름을 나타내는 항목들을 변수라고 하며, 변수 아래로 위치하고 있는 데이터들을 관찰치라고 한다.
관찰치는 크게 숫자형(numeric)과 문자형(character)으로 구분할 수 있다. 숫자형은 사칙연산이 가능한 데이터를 의미한다. 문자형은 남, 여로 표현하는 성별과 같이 문자로 표현된 데이터를 의미하는데, 문자형 관찰치의 경우 숫자로 코딩하는 것이 데이터 핸들링에 유리하다. 하지만 문자형 관찰치가 숫자로 표현되어도 사칙연산이 가능한 것은 아니기 때문에 주의가 필요하다.
측정 수준에 따른 변수의 구분
(확률)변수는 측정 수준에 따라 이산형 변수와 연속형 변수로 구분이 가능하다. 이러한 변수의 속성은 데이터 분석 시, 분석 방법을 선택하기 위한 중요한 근거가 된다.
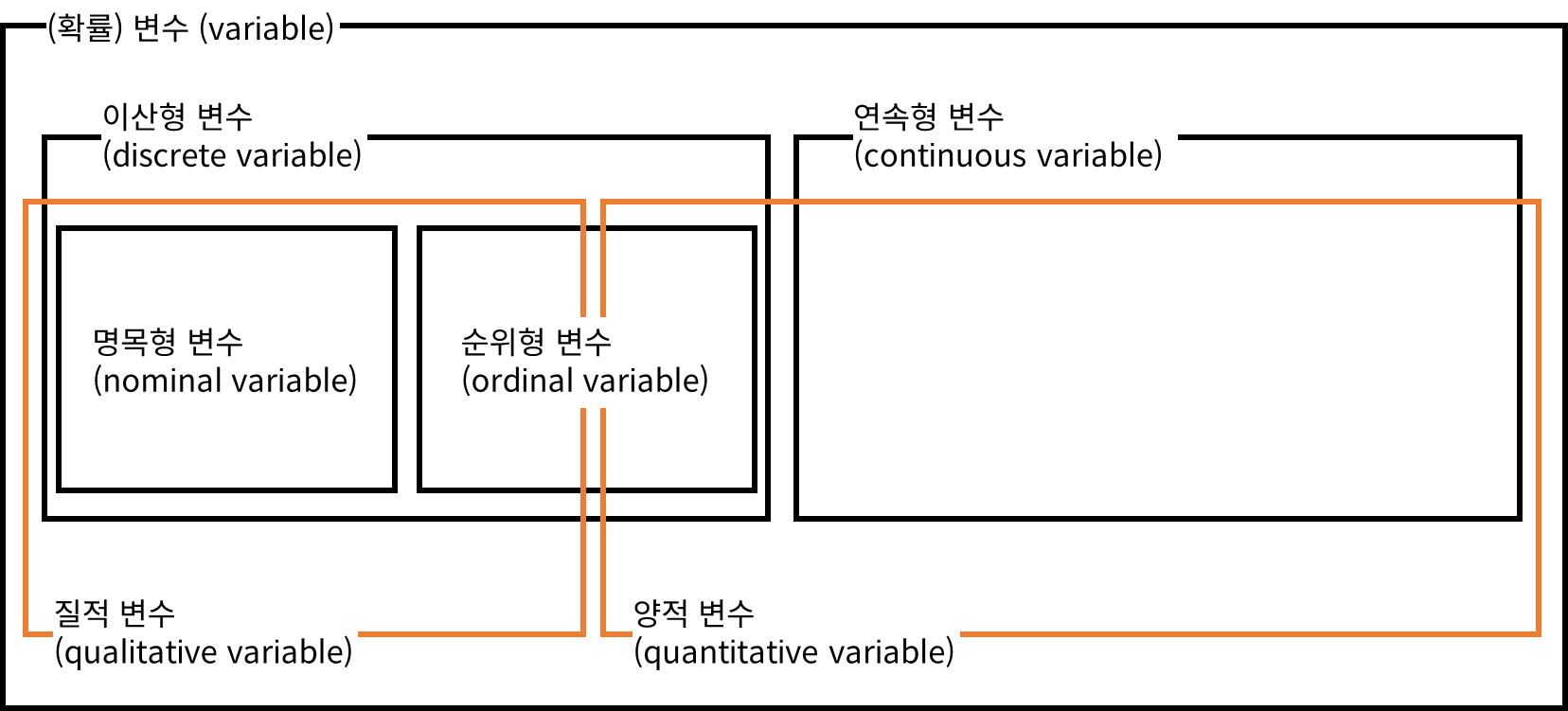
이산형 변수(discrete variable)는 어떤 구간 내에서 취할 수 있는 값이 한정되어 있는 변수로, 셀 수 있는 변수(countable vaiable)이다. 이산형 변수는 명목형 변수(nominal variable)와 순위형 변수(ordinal variable)로 다시 구분하는데, 명목형 변수는 성별이나 혈액형과 같이 값을 이용하여 데이터를 분류할 수 있는 변수(크다, 작다의 개념이 없는 변수)를 의미하며, 순위형 변수는 학력 수준이나 만족도와 같이 값이 크다, 작다의 개념을 가지고 있는 변수를 의미한다. 명목형 변수와 순위형 변수의 특징을 정리하면 다음과 같다.
| 명목형 변수 | 순위형 변수 |
| • 순서의 의미가 없다. → 평균을 계산하는 것이 의미가 없다. • 셀 수 있다. → 퍼센트(비율)로 표현이 가능하다. |
• 순서에 의미(크다/작다, 높다/낮다 등)가 있다. → 평균을 계산할 수 있다. • 셀 수 있다. → 퍼센트(비율)로 표현이 가능하다. |
연속형 변수(continuous variable)는 수치적인 의미를 가지고 소수점으로 표현이 가능한 변수로, 셀 수 없는 변수(uncountable variable)이다. 연령, 체중, 키 등이 연속형 변수에 해당한다. 이산형 변수와 달리 연속형 변수는 실제로 물리적인 양이 존재한다. 연속형 변수는 범주화를 통해 이산형 변수로 변환할 수 있다. 예를 들어 나이라는 변수는 연속형 변수이지만, 10~19세까지를 10대, 20~29세까지를 20대와 같이 범주화한다면 해당 변수는 이산형 변수가 된다.
이산형 변수와 연속형 변수가 아닌, 양적 변수(quantitative variable)와 질적 변수(qualitative variable)로 구분하기도 한다. 연속형 변수와 일부 순위형 변수(ex. Likert Scale)가 양적 변수에 해당하며, 명목형 변수와 객관적 순위형 변수(ex. 학력수준)가 질적 변수에 해당한다.

양적 변수에 해당하는 리커르트 척도(Likert Scale)와 같은 일부 순위형 변수들은 연속형 변수는 아니지만, 각 간격 사이에 물리적인 양이 같다고 가정하고 통계적 추론을 할 수 있다.
'Data Science > 통계학' 카테고리의 다른 글
| 통계학 | 이산형 확률 분포와 연속형 확률 분포 간단 정리 (1) | 2024.01.24 |
|---|---|
| 통계학 | 확률과 베이즈 정리(Bayes' rule) (1) | 2024.01.21 |
| 통계학 | 기술통계량 : 대표값과 산포도 (0) | 2024.01.06 |
| 통계학 | 모집단과 표본 및 통계학적 기술과 추론 (0) | 2024.01.05 |